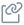Introduction
Large Language Models (LLMs) are revolutionizing industries, from powering chatbots to driving scientific research. Their ability to process vast datasets and generate human-like text has made them indispensable tools. However, their effectiveness depends on their reliability and ethical soundness. To fully harness power of LLMs, rigorous testing is essential.
What is LLM testing?
LLM testing involves evaluating large language models to ensure they perform as expected, deliver accurate and relevant responses and adhere to ethical principles. It's a multi-faceted process that includes:

Why is LLM testing crucial?
LLM testing ensures model reliability, accuracy, fairness and compliance with responsible AI principles. Without thorough evaluation, risks include inaccurate outputs (e.g., biased responses, misinformation) and failure in critical applications. Testing enables early issue detection, allowing developers to refine models and build trust in AI.
How do we evaluate LLMs?
LLM evaluation assesses performance, responsible AI and functionality ensuring models meet user, ethical and operational requirements. A clear definition of the model's purpose (e.g., creative content, factual answers) is crucial for selecting appropriate testing methods and metrics.
Evaluation mechanism
- Offline evaluation: Tests model during development using predefined datasets to identify areas for improvement
- Online evaluation: Assesses real-world performance by analyzing user interaction logs
CI/CD integration: Embeds automated testing within the CI/CD pipeline for continuous improvement and streamlined deployment
What do we evaluate?
LLM evaluation focuses on:
- Functional correctness: Ensuring the model performs as intended
- Responsible AI: Adhering to ethical considerations, fairness and security
- Performance efficiency: Assessing the model's efficiency, scalability and resource usage
Category | Components | |
| Functional Testing | Feature validation | |
| Prompt validation | ||
| Exploratory testing | ||
| Regression testing | ||
| Unit testing | Adversarial testing, property-based testing, example-based testing, auto evaluation | |
| Usability testing | UI testing, error handling, context awareness, accessibility | |
| Response accuracy | Relevance, coherence, completeness, consistency | |
| Comparative analysis | ||
| Integration validation | ||
| Multi modal validation | ||
| Responsible AI testing | Bias, fairness, toxicity, transparency, accountability, inclusivity, privacy, security, reliability and safety | |
| Performance testing | Latency | Throughput, response time |
| Scalability | User load, traffic load, large data volume | |
| Resource Utilization | CPU, GPU, memory, disc usage | |
Indexes for AI pillars:
AI pillars | Description |
Explainable AI | Measures how well model decisions can be explained |
Fair AI | Quantifies the level of fairness in the model's predictions |
Secure AI | Evaluates the model's robustness against threats |
Ethical AI | Measures compliance with ethical guidelines |
Overall evaluation:
Combines individual indices (explainability, fairness, security, ethics) for an overall evaluation.
Thresholds:
- Index ≥ x: Indicates trustworthiness and readiness for certification
- Index < x: Suggests the need for improvement
Testing methodologies
- Automated testing: Uses predefined datasets and benchmarks (e.g., BLEU, ROUGE, Perplexity) to evaluate LLM performance
- Peer LLM evaluation: Employs LLMs to evaluate other LLMs, using critiques, rubrics or metrics
- Scenario-based testing: Simulates real-world scenarios to assess practical usability
Conclusion
Rigorous testing of Large Language Models (LLMs) is imperative to ensure their reliability, fairness and alignment with ethical principles. By systematically evaluating LLMs through functional, responsible AI and performance testing, organizations can identify and address potential biases, inaccuracies and security vulnerabilities.
A robust testing framework, encompassing offline and online evaluations as well as CI/CD pipeline integration, is essential for continuous improvement and deployment. By prioritizing LLM testing, organizations can unlock the full potential of AI, deliver innovative solutions and build trust with users. As the field of AI continues to evolve, so too must our commitment to rigorous testing to ensure the development of ethical, reliable and beneficial LLM applications.