Introduction
Inherent to the IoT is the generation of large volumes and a variety of time series telemetry, which makes Generative AI (GenAI) applicable to multiple facets of a typical IoT environment. In this series of articles on GenAI and IoT, we explore several facets where GenAI and IoT intersect.
The previous post in this series — Introduction to Generative AI in IoT: Capabilities and Limitations — defines and describes GenAI. In this post, we focus on understanding data gaps.
Data gaps have existed since the dawn of the Digital Age and have been mitigated in the past using several technologies and tools. We explore what data gaps are, the root causes for their existence and their diverse types.
Understanding data gaps in AI
ML algorithms require a sufficiently large, curated dataset to create a model accurate enough to meet expectations. The size of an “adequate” dataset depends on the chosen ML algorithm and the expected results in the context and nuances of the use cases. It dataset needs to contain the variations representing the conditions that the model needs to detect, classify, analyze, etc. Standard terms for such variations include drift, noise, errors, failures and exceptions. In other words, this dataset needs to contain the range of values for each telemetry but also all the combinations of the conditions — particularly the rare yet critical conditions, like a machine breakdown.
Data gaps in the enterprise
Let us examine the data gaps and their causes in the operational aspects of an enterprise.
Enterprises often purchase and deploy equipment, from simple coffee/vending machines to complex systems like manufacturing robots, vehicles, etc. Often, cost pressures drive purchasing decisions to obtain equipment to meet core requirements. Moreover, complex equipment often requires detailed configurations designed by domain experts before it is deployed for safe and productive operational/production use.
Insufficient
Imbalance
Data Gaps are frequently caused by configurations developed and tested in "lab" environments which often do not have the variety, variances and diversity of operational environments. Since data gaps are invisible, their discovery journey occurs only after a model provides inexplicable results. Many times, the high cost of supplies and labor for such equipment constrains the labs from generating a sufficient volume of data for ML/AI to be effective. In other words, the real data is sufficient for the initial machine validation, but there just is not enough data for machine learning and predictive analytics, and thus, there is a data gap.
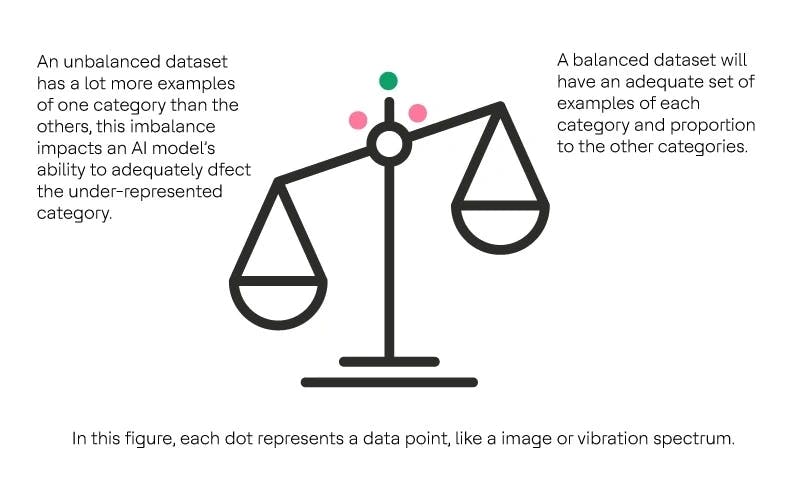
Illustration Scenario 1: Issues in pharma manufacturing equipment causes production stoppages
The imbalance was the lack of sufficient failures after the equipment was moved, which in turn impacted the baseline pattern of vibrations.
Illustration Scenario 2: Automatic damage assessment and repair estimation for vehicle insurance claims
The imbalance was the lack of the types of vehicle damage for all brands, makes and models of vehicles.
Texture
Equipment telemetry in IoT is typically multitudes of parameters that subtly influence each other; one can mentally visualize this data to have a texture. This texture is unique to each equipment, even for the same make and model installed in different parts of a facility. Rarely is the texture smooth as glass; however, such textures are too subtle for us to discern.
Illustration Scenario 1: Issues in pharma manufacturing equipment cause production stoppages
The baseline texture of the equipment vibrations in the first location was different at the new location as the neighboring heavy equipment vibration characteristics caused the predictive AI model to incorrectly identify anomalies.
Drift
Another form of a data gap is “data drift,” where new data variations slowly accumulate over time. When these new variations are sufficiently large, the model becomes less accurate and needs to be updated (re-trained) with new curated data. Some of the reasons for data drift are:
Environment
Any change in the equipment's operating environment, whether momentary or sustained, causes the equipment data to vary somewhat from the norm but not significantly enough to trigger alerts (or may incorrectly trigger an alert). These are typically termed false negatives or false positives and are undesired since false positives impact productivity.
Illustration Scenario 1: Issues in pharma manufacturing equipment cause production stoppages
Sometimes, equipment nearby affects the monitored equipment; this could be a heavier forklift causing a more significant vibration impact or an upgraded HVAC chiller affecting ambient temperature or different viscosity lubricant.
Manufacturing changes
Equipment manufacturers need to adapt to market conditions, including sourcing parts from different suppliers meeting the same specifications. However, even seemingly identical parts can be different enough to affect the telemetry that the predictive model expects.
Illustration Scenario 2: Automatic damage assessment and repair estimation for vehicle insurance claims
A change in the supplier of steel or crumple zone design changes causes the damage to look different from a make/model manufactured just a few years apart, causing a significantly different damage pattern (or estimated repair cost).
Aging
All equipment ages with use, and the wear and tear on its parts occur at different rates based on a range of factors. In turn, the aging parts affect equipment performance and associated telemetry.
Let us illustrate these root causes of data drift using the vibration signatures of equipment. Rotating parts are common in a diverse variety of equipment; some examples are desalination pumps, building elevators/escalators, MRI scanners and transportation vehicles (planes, ships, trains, automobiles). They generate baseline vibration signatures when such equipment is operating in their typical environment, and anomalies from the baseline are key to detecting degradations and impending failures in the equipment. The equipment's vibration sensor may be momentarily affected by a forklift or other heavy vehicle driving past it — a change in the environment. A replaced gearbox or belt from a different supplier introduces slightly different dynamics — a change in manufacturing variations and aging.
In summary, even enormous datasets often have data gaps for different conditions, ranging from infrequent to rare. Depending on the criticality of these conditions to different use cases, these data gaps may have a significant impact.
Key takeaways
- There are multiple types of data gaps, and they exist in all datasets
- The criticality of data gaps varies across different use cases
Conclusion
Having established a sound understanding of the numerous types of data gaps, the next article will focus on the different approaches to address them with discriminative and generative AI.