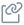: A Technique to Detect Data Change")
Background
The purpose of this blog is to provide a comprehensive understanding of Change Data Capture (CDC), as well as its significance and the techniques to attain it.
Change Data Capture (CDC)

Change Data Capture (CDC) is a technique or process that facilitates the monitoring and capture of data modifications within DB systems.
Change Data Capture (CDC)
Change Data Capture (CDC) is a technique or process by which data changes can be tracked and captured in database (DB) systems. It facilitates finding data changes that occur in DBs after a point and validating the anomalies, if present. These data anomalies may further require analysis to find the root cause and fix the problems in application business logic in case there are any. CDC is best suited for modern architectures (e.g., cloud platforms) that are highly efficient in moving and providing data across the internet or within the boundary of a specific network.
Where can CDC be applied?
Three major cases have been identified where CDC can be applied. However, its applicability is not restricted to just the below three.
Case 1: CDC is beneficial for data changes made in legacy systems where the Database Schema (DBSchema) does not have any timestamp column or transactional logging enabled. In fact, accommodating any new change inside the DBSchema and in business logic will be error-prone, leading to the risk of full or exhaustive regression testing.
Case 2: CDC can be advantageous for use cases where legacy modernization is on the way to fully outride the legacy applications after their successful modernization to the latest technologies or platforms. To understand this better, let us assume there are two systems that are running within the same application, in which one is the legacy system and the other is the modernized version of the application. For a successful transition, there is a need to verify the unforeseen data anomalies that may arise. This process will be helpful in judging the accuracy of modernization, which will streamline the legacy system outride process completion.
Case 3: CDC can be helpful in modern systems where the datasets are too large and required to be stored typically in cloud data warehouses or data lakes. These data are utilized by AI/ML to perform further predictions and analytics, as well as for BI reporting. These processes require loading the complete large datasets, which can be very expensive and highly CPU- and time-intensive, which is where CDC can be of help.
CDC approaches by default
Though there are several ways available to instrument CDC, some of them are not present in legacy DBs. In order to avoid the effect on transactions and performance degradation on the DB server, the Database Administrators (DBAs) are more interested in embedded CDC, which is a log-based CDC internally implemented in SQL Server, Oracle and some other databases. However, the concern persists regarding the application of CDC for the legacy systems, given this internal feature is missing. Although this question remains unanswered, there are ways to get the CDC out of it.
Applying CDC
Applying CDC is a way by which we can collect or gather the data that has been changed due to commands like inserts, updates and deletes. However, gathering such data is itself a tedious task, as there is a possibility that in some legacy systems, the transactional logging or timestamp will not be implemented (examples include core legacy applications and DB systems).
For Case 1: In this scenario, CDC can be achieved by fetching datasets from legacy systems and feeding them into any Online Analytical Processing (OLAP) system. These are the systems where a more comprehensive range of SQL statements have been provided to process large datasets on highly available and scalable systems. By applying CDC, the user can figure out and capture the data changes for further analytical processing, if required. Here, loading the complete large datasets is very costly and can be CPU- and time-intensive.
Below are the steps to explain the flow of the above diagram:
Step 1: Fetch the datasets from the legacy systems
Step 2: Depending on the need, some transformation may be required with the source datasets
Step 3: Feed the datasets to OLAP systems (be it on the cloud or on-premises)
Step 4: From the OLAP, the data changes captured after the CDC will now become available for analytics, processing and reporting
For Case 2: To achieve an effectively modernized system, the detection of anomalies between the legacy and the modernized systems becomes crucial. There are foolproof chances of getting log-based data from modernized systems, but the chances of gaining the data from legacy systems are very low. In such a scenario, CDC can be achieved by feeding the datasets fetched from both these systems into any OLAP system. The datasets from both systems, when processed with OLAP systems, can assist in detecting data anomalies. By applying CDC, we can figure out and capture the data changes from both systems. The changes/anomalies found can be reported or processed for analytical processing. Similar to the first case, loading the complete large datasets is very costly and both CPU- and time-intensive.
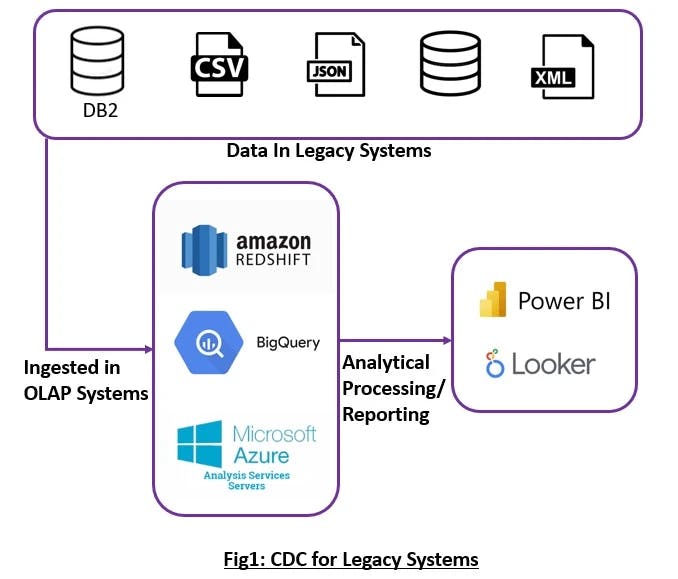
Below are the steps to explain the flow of the above diagram:
Step 1: Fetch the datasets from the legacy and modernized systems
Step 2: Depending on the requisite, some transformation might be required with the source datasets on both legacy and modernized
Step 3: Feed the datasets from both sources to OLAP systems (be it on the cloud or on-premises)
Step 4: From the OLAP, the CDCed data will now become available for analytics, processing and reporting.
For Case 3: In this scenario, the CDC can be achieved by fetching datasets from modern systems, as these are log-based, timestamp-based or trigger-based systems. From here, the latest datasets can be fetched and processed in OLAP systems whenever needed. Here, the CDC may not be costly, CPU-intensive or time-intensive, as we are dealing only with incremental data.
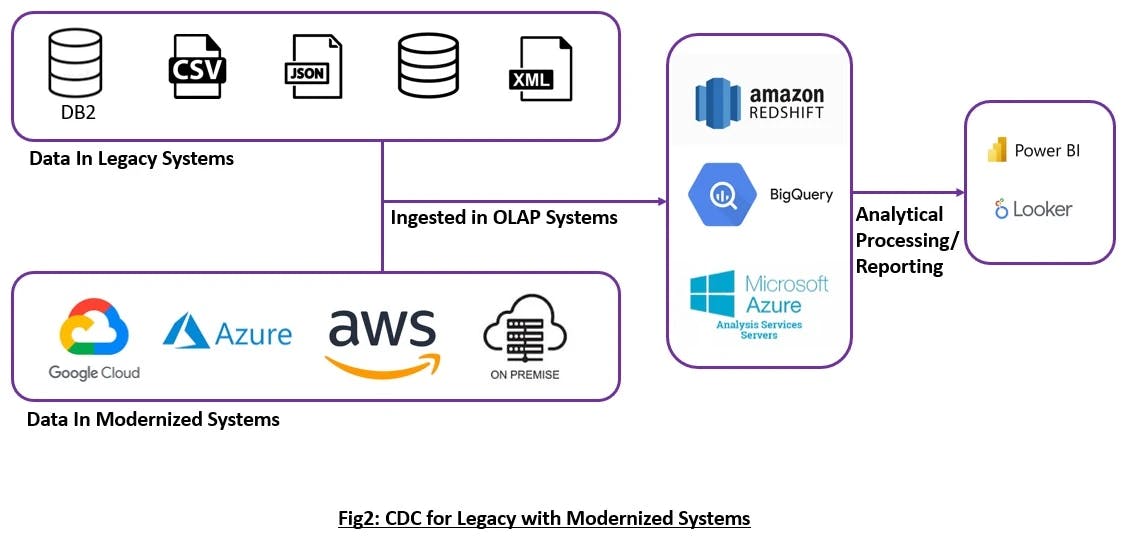
Below are the steps to explain the flow of the above diagram:
Step 1: Fetch the entire datasets from the source systems only once
Step 2: Depending on the need, some transformation might be required with the source datasets
Step 3: Feed the datasets to OLAP systems (be it on the cloud or on-premises)
Step 4: Next time onward, only the transaction logs will be fetched, and using the log miner, the changes will be added to the OLAP systems
Step 5: From the OLAP, the CDCed data will now become available for analytics, processing and reporting.
Conclusion
CDC will be helpful in identifying the data changes in a single or multiple systems. It can be helpful in avoiding the risk of complete regression testing. Some other ways are available to get the CDC of the DBs along with the freedom and scope for further customizations. In this blog, we have given a walkthrough of the CDC and how we can apply it to take its advantages to play with the analytics or reporting of the CDCed data.
References
https://en.wikipedia.org/wiki/Change_data_capture
https://medium.com/google-cloud/bigquery-table-comparison-cea802a3c64d