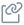In the rapidly evolving field of AI, language models have become a cornerstone of many modern applications, from chatbots to content generation tools. While large language models (LLMs) like OpenAI’s GPT series have garnered significant attention for their impressive capabilities, they present challenges. High computational costs, resource demands and concerns about data privacy are some of the factors that have prompted a shift toward more specialized solutions.
This is where small language models (SLMs) come into play. Designed to meet the specific needs of businesses and industries that require tailored language processing capabilities, SLMs offer a more focused and efficient alternative. Unlike LLMs, SLMs are optimized for efficiency, making them accessible to a broader range of users without compromising performance for niche applications. As businesses seek smarter, more sustainable AI solutions, understanding the role of SLMs is crucial in navigating the future of language processing.
In this blog, we’ll explore what SLMs are, their relevance in today’s business landscape, how they compare to LLMs and what the future holds for this emerging technology.
Understanding the basics: SLMs vs LLMs
An SLM is a compact Gen AI model with fewer parameters and a smaller neural network architecture than an LLM. SLMs are trained on a smaller, more specific and often higher-quality dataset compared to LLMs.
Imagine language models as parts of a vast puzzle. LLMs are like the enormous, detailed pieces that form the intricate and expansive sections of the puzzle. They handle complexity and bring together diverse elements to create a broad, comprehensive picture. SLMs, on the other hand, are smaller, more specialized pieces—those essential shapes that fit perfectly into specific areas, completing the puzzle in ways that the larger pieces can't.
Just as both large and small pieces are vital in solving a puzzle, LLMs and SLMs each plays a crucial role in language processing. LLMs offer the breadth and depth needed for complex tasks, while SLMs provide the precision and focus required to complete simpler, more specific tasks. In other words, SLMs fill in the gaps, ensuring that every aspect of the puzzle comes together seamlessly.

Comparative analysis
| Aspect | SLMs | LLMs |
|---|---|---|
| Parameters | Millions to a few billion | Dozens or hundreds of billions to trillions |
| Performance | Perform better for simpler or specific tasks | Excel in complex language understanding and generation |
| Dataset | Domain specific | Trained on a large data source |
| Training and resources | Require less computational power, memory and storage | Require a significant amount of computational resources, memory and storage |
| Price | Relatively cheaper | Expensive |
| Use cases | Embedded systems, mobile applications and IoT devices | Advanced chatbots, content creation and complex translation systems |
| Deployment | Easier to deploy on various platforms | Often necessitate specialized hardware and powerful cloud servers |
| Adaptability | Can be quickly fine-tuned for specific tasks or domains | Offer greater flexibility but require significant effort to fine tune |
| Security | Lower risk of exposure due to smaller deployment footprint | Higher risk due to larger attack surface and dependency on cloud infrastructure |
SLM use cases
While LLMs excel in handling complex and broad-ranging tasks, SLMs offer distinct advantages in specific scenarios:
- Resource efficiency: SLMs require significantly less computational power and memory, making them cost-effective to deploy and operate, especially in resource-constrained environments.
- Retail: SLMs can power in-store kiosks that provide customers with product information and personalized recommendations without requiring extensive backend infrastructure.
- Faster response times: Their smaller size allows SLMs to process and generate responses more quickly, which is crucial for real-time applications.
- Customer service: In the telecommunications industry, SLMs can be used in call centers to swiftly handle routine customer inquiries, reducing wait times and enhancing customer satisfaction.
- Energy efficiency: SLMs consume less energy, making them a sustainable choice, particularly for companies focused on reducing their carbon footprint.
- Smart home devices: SLMs can be integrated into smart home assistants to efficiently manage tasks like controlling lights and appliances, thus providing eco-friendly solutions.
- Deployment flexibility: SLMs are easily deployable on edge devices and IoT systems and in environments with limited connectivity.
- Healthcare: In remote or rural healthcare settings, even in areas with limited Internet access, SLMs can be deployed on portable devices to assist with patient diagnostics and record keeping.
- Cost-effectiveness: For many tasks, the performance gap between SLMs and LLMs may be minimal, making SLMs a more economical solution without compromising quality.
- Education: Educational institutions can use SLMs to create affordable, personalized learning tools and automated grading systems, making advanced educational resources accessible to a broader audience.
- Specialization: SLMs can be fine-tuned for specific tasks or domains, delivering highly specialized performance without the overhead of a larger model.
- Finance: Financial institutions can fine-tune SLMs for tasks like fraud detection or risk assessment, providing tailored, efficient solutions to meet specific needs.
While LLMs are undeniably powerful, SLMs offer practical advantages in efficiency, speed and cost-effectiveness, making them an intelligent choice for many real-world applications.
Market leaders
The following table includes SLM market leaders along with their innovations and advancements.
| Parent company | Model | Year of release | Parameters | Context length | Key features |
|---|---|---|---|---|---|
| Microsoft | Phi-1 | June ’23 | 1.3B | 2K | State-of-the-art performance on Python coding benchmarks. |
| Phi-1.5 | Sept ’23 | 1.3B | 2K | Performance comparable to models 5x larger, focused on common sense reasoning and language understanding. | |
| Phi-2 | Dec ’23 | 2.7B | 2K | Outstanding reasoning and language understanding capabilities; matches or outperforms models up to 25x larger. | |
| Phi-3-mini | June ’24 | 3.8B | 4K and 128K | First in its class to support a context window of up to 128K tokens, optimized for various hardware. | |
| Phi-3-small | April ’24 | 7B | 8K | Outperforms much larger models, including GPT-3.5T. | |
| Phi-3-medium | April ’24 | 14B | 8K | High performance across language, reasoning, coding and math benchmarks. | |
| Mistral AI | Mixtral 8x7B | Dec ’23 | 56B | 32K | Mixture-of-experts model that uses specialized models for different tasks, with a gating mechanism to choose the best one for each input; excels in code and reasoning benchmarks. |
| Meta | LLaMA 3.1 | July ’24 | 8B, 70B, 405B | 128K | Excels in general knowledge, math, tool use, synthetic data generation and multilingual translation. |
| Gemma 7B | April ’24 | 7B | 8K | Efficient deployment, strong performance in question answering, reasoning, math and coding. |
The following graph displays the relationship between model size and quality, highlighting how advancements in model architecture and training data have impacted their performance.
SLM challenges that need to be addressed
The analysis of Hughes Hallucination Evaluation Model (HHEM) Leaderboard highlights how newer SLMs are closing the performance gap with LLMs, but several challenges remain.
| Type | Model | Hallucination Rate | Factual Consistency Rate |
|---|---|---|---|
| SLM | Phi-2 | 8.5% | 91.5% |
| Phi-3-mini-4K | 5.1% | 94.9% | |
| PhiPhi-3-mini-128k | 4.1% | 95.9% | |
| Mixtral 8x7B | 9.3% | 90.7% | |
| LLaMA 3.1-405B | 4.5% | 95.6% | |
| Gemma 7B | 7.5% | 92.5% | |
| LLM | GPT-4 Turbo | 2.5% | 97.5% |
| GPT-3.5 Turbo | 3.5% | 96.5% | |
| LLaMA-2-70B | 5.1% | 94.9% | |
| Google Gemini 1.5 Pro | 4.6% | 95.4% |
The HHEM Leaderboard evaluates the frequency of hallucinations in document summaries generated by LLMs using a dataset of 1,006 documents from multiple public datasets, primarily the CNN/Daily Mail corpus.
- Hallucination rate: Newer SLMs like Phi-3-mini-128k (4.1%) and LLaMA 3.1-405B (4.5%) show lower hallucination rates compared to initial models like Mixtral 8x7B (9.3%). However, they still lag behind LLMs like GPT-4 Turbo, which boasts a rate of 2.5%.
- Factual consistency rate: GPT-4 Turbo leads with a 97.5% factual consistency rate, while Phi-3-mini-128k (95.9%) and LLaMA 3.1-405B (95.6%) also show strong performance but need further improvement.
LLMs like GPT-4 Turbo, with low hallucination rates and high factual consistency rates, set high standards. While newer SLMs like Phi-3-mini-128k and LLaMA 3.1-405B are catching up, they must overcome challenges in accuracy and reliability to match the performance of top LLMs, while maintaining lower computational costs and faster processing times.
Looking ahead
As we consider the future of SLMs, their success will largely depend on how well they can balance performance with efficiency. With the growing demand for AI-driven applications, SLMs need to prove that they can consistently deliver accurate and contextually relevant outputs while keeping computational costs and energy usage low. Their ability to adapt to various use cases and integrate seamlessly into existing systems will also be crucial.
Ultimately, the future of SLMs will be determined by their capacity to offer robust, scalable solutions that cater to the diverse needs of users and industries. As AI continues to evolve, the role of SLMs will likely become more prominent, especially in environments where efficiency, specialization and sustainability are key. This invites us to reflect on the future of AI and the critical factors that will shape its trajectory, positioning SLMs as a vital component of the AI landscape.
References