

Introduction
As enterprises transition from the exploratory stage of GenAI applications to production-grade scaled applications, they face several challenges. One key challenge is the cost and response time of large language models (LLMs), particularly when multiple concurrent users interact with the GenAI application.
Like any other caching mechanism, LLM can help address these GenAI application concerns. By introducing and implementing an LLM caching layer during the request/response exchanges, the application's performance can be significantly improved. Cache hits avoid LLM-based processing, and the results are retrieved directly from the persistent cache entries, resulting in a performance boost.
This blog will detail the workings of LLM caching and explore retrieval-augmented generation (RAG)-based GenAI application design with and without LLM caching. It will also discuss the unique design considerations and challenges around caching language model responses, explore different caching approaches and provide a comparative study of application performance with LLM caching.
LLM cache
In computing, a cache is a hardware or software component that stores data, enabling faster retrieval for future requests. The stored data may result from a previous computation or a copy of information residing elsewhere. A cache hit occurs when the requested data can be found within the cache, while a cache miss signifies that the data is unavailable. Cache hits are served by reading the data directly from the cache, faster than recomputing a result or retrieving it from a slower data store. Consequently, the more requests that can be satisfied from the cache, the faster the overall system performance.
The concept of an LLM cache follows this same fundamental design principle. In the context of LLM-powered GenAI applications, the request-response pairs serve as the primary entries for LLM cache implementation. The LLM cache is queried whenever a future request is made to find a similar entry. If a matching response is located within the cache, it is directly returned to the user, resulting in an LLM cache hit. Conversely, if no matching entries are found in the LLM cache, the actual LLM call generates the response, constituting an LLM cache miss.
LLM cache design considerations
LLM cache data entries—The LLM calls generated request/response pair is persistently stored to serve as cache entries. The requests/queries would also be stored as vector embeddings to enable semantic search.
LLM cache seed—The mechanism/process/schedule to maintain persistent cache store. Ideally, each LLM hit would be stored in the cache to enable cache serving for a similar next request.
LLM cache purging—The cache entries may become obsolete due to changes in the respective knowledge sources. Cache entries must be refreshed as per schedule or by dynamic trigger whenever the underlying data sources are updated to avoid irrelevant or obsolete responses.
RAG-based implementation with LLM cache
In RAG-based GenAI application design, the user's queries are answered from the defined vectorized organization's knowledge sources. Here's how the LLM cache infusion to the RAG-based application can enhance the overall performance:
- The user interacts with the application, submitting a specific query
- The user's query is converted into a vector embedding, and semantic search techniques are utilized to find a relevant match within the cached entries
- The semantic search is performed on the cache entries to find matching responses:
- If a close match is found based on the defined similarity search threshold, it is considered a cache hit and the corresponding response is retained from the matched cached entries
- If a close match is not found based on the defined similarity search threshold, it is considered a cache miss and the request is forwarded to be fetched from the underlying RAG/LLM layer
- In case of a cache hit, the matched response is sent back to the user (no actual LLM call is required for cache hit response)
- In case of a cache miss, where no similar close cached data items are available, the user's request is forwarded to the actual knowledge store for a similarity match
- The top K relevant data items are fetched from the knowledge store and, along with the original user query, are sent to the LLM for response generation
- The final LLM-generated response is sent back to the user, and simultaneously, the cache is updated with this response to facilitate future cache hits for relevant queries
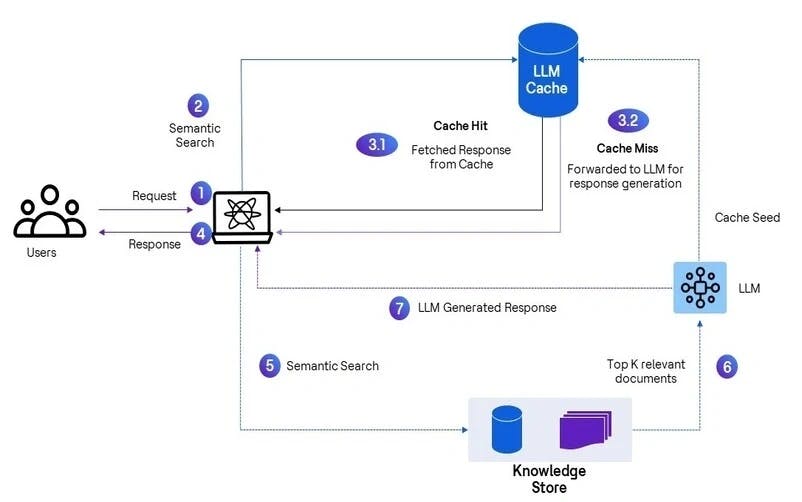
Figure: RAG implementation with LLM cache
As we have seen, LLM cache hits avoid the actual LLM calls. Below is how the percentages of cache hits impact overall response generation performance and LLM costing.
Performance evaluation
In this experiment, we have leveraged ChromaDB as the knowledge store (Vector DB) and Anthropic's Claude v2 model, accessed via Amazon Bedrock, as the large language model (LLM) for response generation. We conducted four iterations, each consisting of ten queries, with varying percentages of LLM cache hits. The performance observations are as follows:
By varying the percentage of LLM cache hits, we could assess the impact of cached responses on the system's overall performance. The performance observations across the four iterations revealed interesting performance patterns and trends. The average response time for ten queries without cache is approximately 2.8 seconds, which is reduced linearly with higher cache hit ratios.
Sustainability factor
There is growing concern regarding the significant energy and water consumption associated with operating large language models (LLMs), often called "Giant Thirsty Monsters" due to their heavy resource demands. This issue poses a critical challenge as the adoption and integration of LLMs continue to rise across various industries and applications.
Implementing LLM cache is important in mitigating this risk factor and driving towards more sustainable LLM usage. By leveraging caching mechanisms, the repeated retrieval and processing of information can be minimized, reducing LLM-powered systems' overall energy and water footprint.
Conclusion
Implementing LLM cache in Generative AI applications can significantly improve performance and reduce costs by avoiding costly LLM calls for repeated queries. The LLM cache can quickly retrieve relevant responses by storing request-response pairs and their vector embeddings, resulting in faster response times and lower computational overhead. The design considerations around cache data entries, seeding and purging are crucial to ensuring the LLM cache remains up-to-date and effective. The RAG-based architecture with LLM cache showcases how the cache can be seamlessly integrated, providing a tangible performance boost.
As organizations scale their GenAI applications, leveraging LLM cache becomes a critical strategy to unlock the full potential of large language models while addressing the challenges of cost and response time.
For a detailed understanding, demonstration or implementation of this solution, please contact us: awsecosystembu@hcltech.com.
References:


