

The mythical Tower of Babel, very often, reflects our own world, where everyone speaks but no one understands each other. So while the inspiration for this article can be attributed to a MYTH, the subject of this article is rooted in firm reality viz. DATA
As the amount of data around us proliferates in unimaginable ways, we are left dealing with two distinct problems. The first is of course using, storing and protecting this data at massive scales and the second is dealing with myriad acronyms, industry parlance, common (mis)understandings; all yielding an alphabet soup of cluttered nomenclature.
This article is an attempt to declutter the nomenclature that is commonly used and very often mis-used, when using the term “DATA” in the context of backup, DR (disaster recovery), archival and CR (cyber resiliency) solutions.
It is important to note the fact that some of these terms tend to be mis-used or mis-construed due to historical reasons; from a time when they were used interchangeably. On the other hand, some of the terms are also new to the industry for which commonly acceptable definitions are still evolving.
Have a look at the picture below as we delve into some terms mentioned therein.
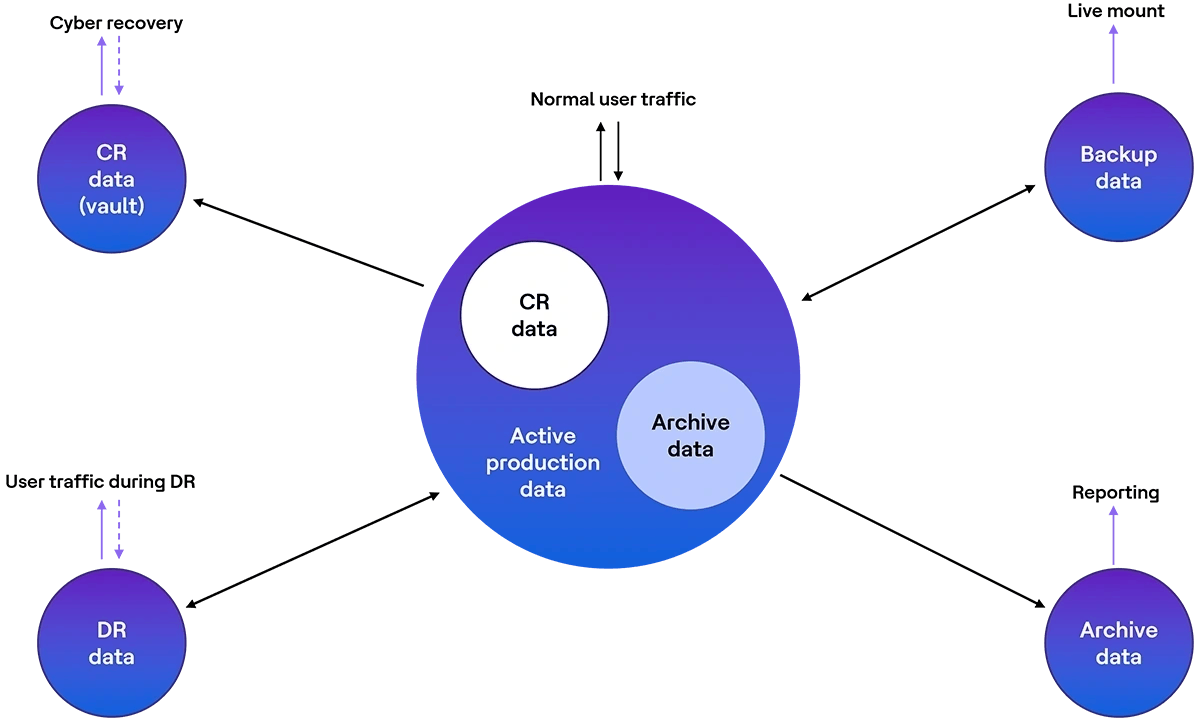
| Data (bucket) | About the data (bucket) | |
|---|---|---|
| Active production data | As the same suggests this data belongs to the production systems which serve your consumers during normal operations. We deliberately do not draw any boundary between DTA (Development, Test & Acceptance) data and Production data, since for all practical purposes, DTA data is still serving your consumers, albeit internal. As you can see in the picture above, the two-way arrow above Production data indicates that this data can be accessed and modified, both, by consumers. Active Production data will be backed up (fully or partially as per policy) and Active Production data will also have a DR copy (fully or partially as per policy) | |
| Archive Data | Archive data refers to that data which is no longer needed and no longer relevant for serving consumers on a day-to-day basis. However, this data is important and relevant. Hence, this data is moved out from the Active Production data (bucket) and stored separately. The separate store for archive data could be in the form of a separate storage area/device, a separate database instance, a separate application instance or something else. The advantage of moving the Archive data out, is that size of the “Active” production data can be reduced, which in-turn can help reduce storage costs, reduce demands on the backup solution and improve app/query performance, to enhance consumer experience. The following example can help clarify the concept. Imagine you have a Supplier management system which stores data for all your suppliers, their orders, their payments and so on, since the year 1990. Now, you could move the data from 1990 to 2000 into a separate storage/ database/ app instance; since this data is no longer in active use but must be retained. This represents your “Archive data”. This data can be used for reporting purposes but cannot be modified externally (notice the uni-directional arrow above Archive data in the picture above). The example above uses the “time” dimension to identify the archive-able data. But any other dimension like geography, entity name or so could be used. Remember that Archive data is typically not backed up, since there is no new incremental data being generated in the archive. Also, Archive data does not have a DR, although, you might keep copies of the archive data for extra protection. | |
| DR data | As the same suggests, DR data is a copy of your Active production (full/partial) data stored at a separate location, enabling you to bring your business back online in case the Production data becomes un-available i.e. the Primary site becomes un-available. The DR data need not be exactly the same size as production data, as you may choose to replicate only a part of the production data. The movement of data (replication of data) from Production to DR side, could be done in many ways including, but not limited to, storage replication or database replication. During a failover scenario, the user traffic is re-directed to the DR site (notice the two-way arrow for the DR data user traffic). Also after failback i.e. when the primary site becomes available again, the (new) data is replicated back to Production (notice the two-way arrow between Production data and DR data) It is important to note that DR data is supposed to enable you to recover from a typical site-failure scenario. The DR data is not intended to recover your business after a cyber event like a ransomware attack. This is where CR (Cyber Resiliency) data comes into picture. There could also be other nuances in terms of how the DR is implemented viz. 2-way vs. 3-way DR, sync vs async replication of data, tiered RTO/RPO for various applications, usage of DR for reporting purposes, active/active vs active/passive setup, among others. | |
| CR data | The terms CR has many evolving connotations. But at its core, CR data, mostly refers to “Crown Jewels” data, or in other words - your most critical data. The two most important features, besides others, that the “Vault” for CR data should provide are “Isolation” and “Immutability”. Notice in the picture above that the arrow from Active Production data to CR data is uni-directional. The ultimate purpose of this CR data is to be able to carry out a clean room recovery or a full cyber recovery, depending upon the resources available at hand. CR data is not intended to be used for other purposes like reporting during normal operations. You may choose to retain more than one copy of the CR data, although this is not the usual practice. Lastly, is an ideal world with unlimited resources, CR data can be used bring business back online and therefore could have new incremental data. In which case it would need a Backup and DR for CR data. However, practically speaking, such setups are a rarity (see the dotted arrow above CR data) There are other nuances here in terms of how Isolation can be achieved or what qualifies as “Isolated” or the question of logical vs physical isolation. Another evolving area here is defining a separate Cyber RPO/RTO (Recovery Point Objective / Recovery Time Objective) specifically for cyber-scenarios, distinct from the well-known RPO/RTO dealing with site-failure scenarios. | |
| Backup data | Backup data must be always viewed in the context of two activities: Backup and Restore. Data could be backed up in many ways including, but not limited to, usage of backup software and database native backup functionalities. With advancements over the years, Backup data can now be put to other uses as well. For example, using live mount, backup data can be used to bring virtual machines online for the purposes of testing or retrieving data. Notice the uni-directional arrow for live mount from the backup data. The live mount VMs are not intended for usage by consumers and thus do not have any new incremental data. It is important to differentiate between Backup data vs DR data and Backup data vs Archive data. While the DR data is intended to be as close to the production data, in terms of its state at any particular point in time; backup data is intended to be a historical log of all the changes that the production data has gone through. So, while the primary intention of DR is the ability to recover your business when the primary site fails, the objective of the backup data is to have an ability to return the data to a particular state in history. Conversely, having a DR setup does not take away the need of having a backup. The backup data will still be needed to roll back to a particular state in history. Infact, in most cases, a copy of the backup data will be also kept at the DR site, enabling the DR site to roll back to a particular state in history. In many cases, the term Backup data is also used inter-changeably with Archive. As explained above, the term Archive Data means that this data is no longer Active and therefore not backed up. However, since the backup data gives you the ability to roll back your data to a particular state in history, it can, sometimes, cater to your archiving needs (the term ‘archive’ then has a narrow connotation). | |
To summarize, while you look at your landscape, the various types of data buckets explained above represent various use-cases / requirements, but at the same time, they also represent additional costs and management complexity.
It is therefore highly recommended that for each data bucket -
- Identify what data each bucket must contain, not every data bucket needs to contain all the data
- Determine the use for each type of data. Each bucket should deliver something unique
- Define the technology needs of each bucket viz. type of storage, number of copies and so on. These will be unique for each bucket.
To know more, you may write to us at HCBU-PMG@hcltech.com.
