

AWS Glue is a serverless service that primarily performs extraction, transformation and loading (ETL) tasks by leveraging Apache Spark, either through the Python PySpark API or the Scala language. It facilitates the movement and cataloging of big data based on the type of solutions used, either Glue crawlers or code-based, to add new data partitions, tables and databases. Data from sources like Amazon RDS and Amazon S3 can be leveraged for Glue jobs and others with targets such as Amazon Redshift. Glue empowers data practitioners to construct end-to-end workflows for orchestrating data-centric pipelines, provisioning them using Infrastructure as Code (IaC) tools as well as integrating and deploying them with ease using AWS Code Build and AWS Code Pipeline.
Existing solution
The following diagram showcases the overall solution architecture and steps.
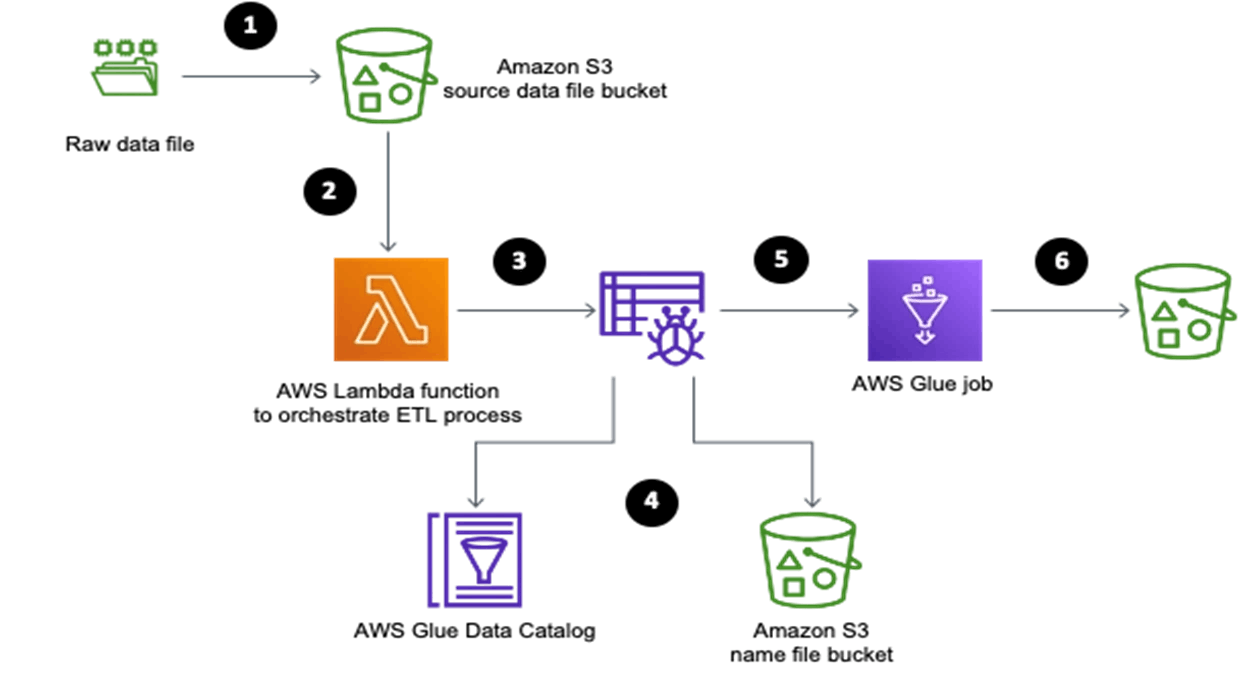
Limitations of AWS Glue
- Limited languages extension – AWS Glue only supports a few programming languages, including Python and Scala
- Limited framework supports – Unable to integrate AWS Glue with any other cloud service system or application
- In AWS Glue, jobs using AWS Glue version 0.9 or 1.0 have a 10-minute minimum billing, while jobs that use AWS Glue versions 2.0 have a one-minute minimum
Industry challenges
- AWS Glue only allows payment for the time taken by ETL job to run. AWS charges an hourly rate based on the number of Data Processing Units (DPUs) used to run the ETL job.
- The large dataset size processed on a daily basis with full snapshots of data, which leads to more usage of ETL processing resources, increases the cost factor.
- In AWS, the user is unable to control the cost until data size or processing resources are decreased, which is not possible, even with transformation logic.
- Most of the data collected is raw from heterogeneous or homogenous sources of data and small files, which leads to problems while transforming the data at subsequent layers.
New proposed solution:
Snowflake is a cloud-based data warehouse that offers a variety of features for data storage, transformation and analysis. One of the benefits of using Snowflake is that it can be easily integrated with other AWS services, such as Amazon S3. This integration makes it possible to migrate data from S3 to Snowflake using:
- The COPY command for historical data migration
- A Snow pipe for real-time data ingestion
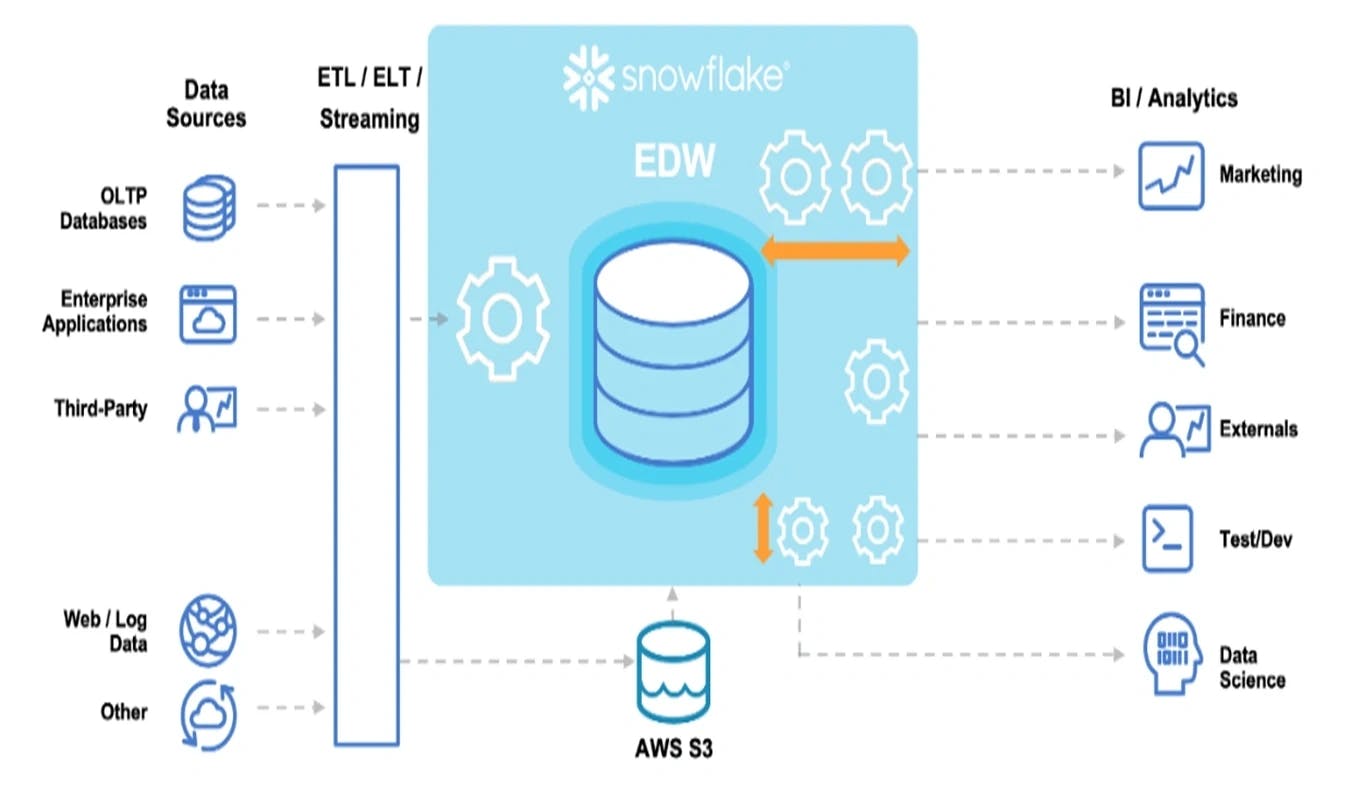
Snowflake architecture
Value creation for a client from time and cost perspectives
We completely disabled the Glue features, which are rarely used in the case of first time dataset configuration or special requests. Going forward, we can continue with delta data processing using the Snowflake DWH, which provides faster processing and computation of data.
In terms of cost, we have 400–500 GB data size daily, which needs to be processed layer by layer and took a day to be completely loaded for D-1 business day data. After implementing the new solution, we reduced the cost by $3,000 monthly, which shows a huge impact and benefits the client from the standpoint of computation charges, resources and time bring reduced to half their previous executions.
References:
https://aws.amazon.com/blogs/big-data/monitor-optimize-cost-glue-spark/
