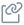Overview
In today's digital age, the volume of data generated daily is staggering, reaching approximately 5 quintillion bytes worldwide. Businesses strive to leverage this wealth of information to stay ahead in the market. However, a critical challenge arises amidst this data deluge: ensuring stakeholders have access to high-quality data for informed decision-making.
Deciphering the data landscape
Consider a leading financial institution in North America grappling with myriad issues within their data and analytics platform on Google Cloud Platform (GCP). These pain points are emblematic of broader challenges faced by organizations navigating the complex landscape of data management:
- Fragmented data: Data is scattered across various locations and departments, hindering seamless cross-referencing and decision-making
- Dataset discovery dilemma: The absence of a cohesive schema or data catalog makes finding relevant datasets difficult, complicating data utilization
- Governance conundrum: Enforcing governance standards across diverse datasets requires robust access control and monitoring protocols
- Data lineage labyrinth: The lack of comprehensive data lineage mechanisms impedes root cause analysis
While the idea of a tailored solution within the Google Cloud environment may be appealing, a more practical approach is necessary due to increasing complexities. It's crucial to explore streamlined methods for overcoming these challenges, enabling improved data accessibility, governance and lineage tracking without relying on bespoke solutions.
Our way forward
The principal objective of the financial institution is the unification of data across various sources and creating a single pane of glass that brings their data together with security and governance. We were sure Goggle Dataplex was the right choice to address the challenges. Google Dataplex is an intelligent data fabric offering that enables organizations to centrally discover, manage, monitor and govern data across multiple sources.
The following are key components of Dataplex.
Implementation approach
Dataplex configuration and setup:
| Steps involved | Description | Design approach |
|---|---|---|
| Step 1: Setting up Dataproc Metastore (V2) | Initially, we established a Dataproc metastore (V2) to leverage the Dataproc cluster for Dataplex processing.
During setup, selecting the "gRPC" protocol is essential, as Dataplex operates solely on this protocol.
The cluster's sizing is tailored based on the data volume and workload size to ensure optimal performance. | We use the developer tier for development and the enterprise tier for production.
Separate metastores are created for each: one for development and another for production, customized to their respective requirements.
The development instance is set to 'xs' size, while the production instance is scaled to one.
MySQL serves as the database engine for the Dataproc metastore.
Key APIs including Cloud Dataplex, BigQuery, Cloud Dataproc and Cloud Composer are enabled for smooth integration and operation. |
| Step 2: Establishing Dataplex lakes and zones | Next, we created Dataplex lakes and zones, organizing data according to different domains and departments. Custom environments with specific packages, such as Python, can be utilized based on project requirements during Dataplex creation. | Similar to the metastore setup, we use the developer tier for development environments, and the enterprise tier is employed for production environments.
Two separate instances of Dataplex lakes and zones are created for development and production environments, each tailored to their respective needs.
MySQL is utilized for the Dataproc metastore, ensuring consistency across the Dataplex environment.
Essential APIs, including Cloud Dataplex API, BigQuery API, Cloud Dataproc and Cloud Composer API, are enabled to support seamless operation and integration across the data ecosystem. |
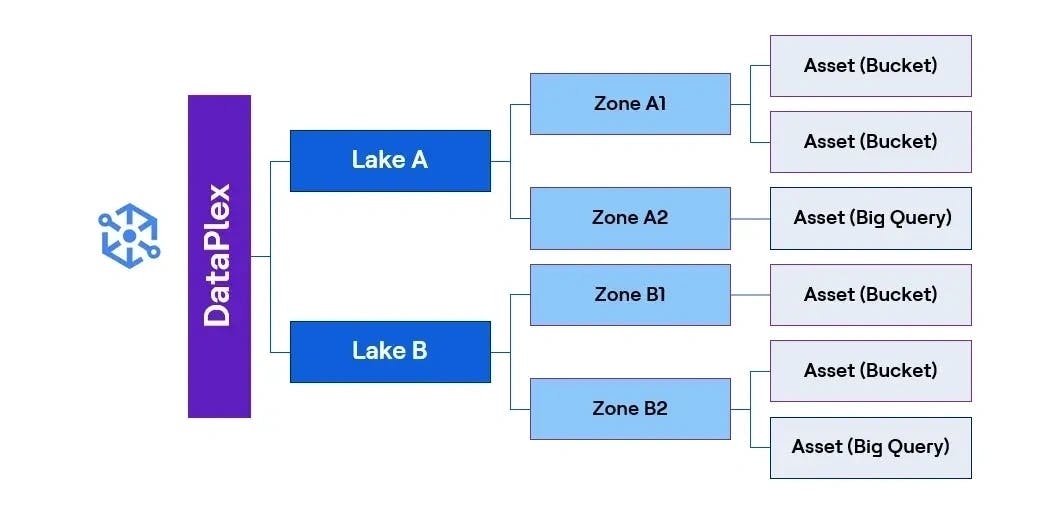
Mapping of assets and enabling the data discovery
By onboarding assets under their respective zones, which can be GCS (Google Cloud Storage) or BigQuery datasets, Dataplex automatically generates metadata and enables data discovery. This allows seamless integration of GCS buckets and BigQuery datasets using SQL in Dataplex Exploration Workbench. As a result, we achieved structured data organization for various services, seamless data exploration across lakes and zones and reduced time to market for operational efficiency. Below is the structure representing the layers created.
Fine-grained access control
We established principles and allocated resource access based on roles, leveraging Dataplex's flexibility to configure access at both the resource and principal levels. Utilizing IAM (Identity and Access Management), we managed principles and implemented fine-grained access control at both the DATA and LAKE levels. This approach enabled granular-level access control and seamless integration and IAM policies, facilitating role-based access control and fulfilling the financial institution's requirement to restrict cross-zone data exploration.
Data processing
We leveraged Dataplex's built-in templates for various data engineering tasks such as data preparation, ingestion, data quality checks and dataflow pipelines. Additionally, Dataplex supports running custom Dataproc serverless tasks, all orchestrated centrally through Composer. By incorporating these tasks into our end-to-end data processing, we achieved improved performance, seamless orchestration and monitoring through Composer. Furthermore, we seamlessly integrated data quality (DQ) processes with existing Composer pipelines, enhancing the overall efficiency of our data workflows.
Data quality
Dataplex provides Auto data quality (AutoDQ) and Dataplex data quality tasks to validate data quality:
- Auto data quality (AutoDQ): AutoDQ automates and simplifies quality definition with recommendations and UI-driven workflows. We can create rules for different dimensions and configure the rule execution for incremental data and full data with a threshold limit.
- Dataplex data quality task: The Dataplex data quality task uses an open-source component, CloudDQ, which can also open up choices for customers who want to enhance the code to their needs. The rules can be configured in a YAML file and referenced from a GCS bucket.
Our design approach encompassed several key elements:
- Custom DQ tasks integrated with Composer for flexibility in workflow orchestration
- AutoDQ was leveraged for selected sources, optimizing efficiency
- Endpoints were established for programmatic data consumption, with data persistence in BigQuery storage and Cloud Logging sinks, and support for integrations with reporting tools like Looker and Google Data Studio
- Dataplex orchestration of execution management for streamlined operations
This approach delivered significant benefits:
- Simplified implementation of data quality dimensions, adaptable to diverse requirements
- Enhanced threshold percentages from 40% to 80%, improving data accuracy and reliability
- Performance improvements and enhanced data stability facilitated faster decision-making processes, driving operational efficiency

Data profiling
We meticulously analyzed source data profiles by configuring and scheduling checks using the Data Profile module within Dataplex. This module identifies key statistical characteristics such as null%, unique% and distribution, providing relevant metrics tailored to column types (e.g., integer or string).
Our design approach involved:
- Creating a data profiling scan linked to a BigQuery table, with the sampling size determined by the criticality of the source data
- Utilizing Looker Studio to generate insights derived from data profiling over a specified period, enhancing data understanding and decision-making processes
In addition to data profiling, we utilized other Dataplex modules to facilitate efficient catalog management and establish governance policies, ensuring comprehensive data management practices.
Manage catalog
- Tag templates: Utilizing tags for data entries provides meaningful context to stakeholders. For example, tags assist in identifying tables having the PII (Personally Identifiable Information) data, data quality scores, data retention policy, etc.
- Entry groups: A traditional approach to data catalogue management, allowing users to create their own entry groups to contain their cloud storage fileset entries and the IAM policies associated with those entries that specify the users who can create, edit and view entries within an entry group.
- Glossary: Primarily used in calculated fields, glossary is a single place to maintain and manage business-related terminology and definitions across the organization.
- Attribute store: Used for creating taxonomies for data attributes that can be attached to datasets.
Conclusion
With its intelligent data fabric, Dataplex empowers enterprises to use their data effectively and power analytics and data science workloads. We view Dataplex as a pivotal tool in unifying data assets, enhancing data management and providing access to high-quality data. Undoubtedly, Dataplex stands poised to revolutionize data lakes and data management, creating a significant impact on enterprise-scale data solutions.
For more information on Dataplex and getting started, reach out to Digital Business team, HCLTech.